CVAE-GAN这篇论文有一些不错的insight可以拿过来使用。
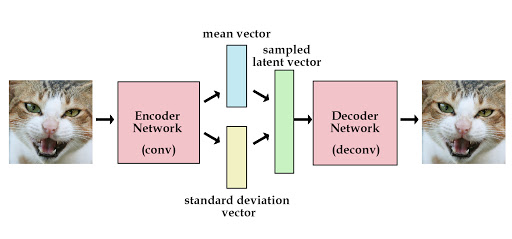
VAE中的encoder是一个神经网路结构用来生成数据样本X中的方差和均值。根据方差和均值得到一个正态分布,从这个分布中采样一个z,该正态分布与标准正态分布之间有一个转换关系,$z=uz+sigma \(, 通过decoder这个神经网络生成新的\)x\(。这个\)x*$可以用来表示新的图像。
衡量decoder和encoder之间的metric是通过用KL-divergence来表示Loss function,具体的推导过程如下,


理解VAE的本质:
它本质上就是在我们常规的自编码器的基础上,对 encoder 的结果(在VAE中对应着计算均值的网络)加上了“高斯噪声”,使得结果 decoder 能够对噪声有鲁棒性;而那个额外的 KL loss(目的是让均值为 0,方差为 1),事实上就是相当于对 encoder 的一个正则项,希望 encoder 出来的东西均有零均值。
那另外一个 encoder(对应着计算方差的网络)的作用呢?它是用来动态调节噪声的强度的。直觉上来想,当 decoder 还没有训练好时(重构误差远大于 KL loss),就会适当降低噪声(KL loss 增加),使得拟合起来容易一些(重构误差开始下降)。反之,如果 decoder 训练得还不错时(重构误差小于 KL loss),这时候噪声就会增加(KL loss 减少),使得拟合更加困难了(重构误差又开始增加),这时候 decoder 就要想办法提高它的生成能力了。
在GAN中,其中的discriminator本质上也是一个metric的判别器,表示生成样本和真实样本之间的JS-divergence。但是GAN存在的问题是
对于cVAE来说,就是存在一个有监督的标签,通过这个标签,只需要将KL-divergence进行一下变换即可:

正式说VAE和GAN的结合:
论文链接: https://arxiv.org/pdf/1703.10155.pdf

cvae-gan的具体实施架构